
مقدمه
با توجه به نیاز مبرم اسپلانک به منابع پردازشی و ذخیره سازی بی شک یکی از مهم ترین دغدغه های سازمانها استفاده حداکثری از منابع موجود و بکار رفته در طراحی اسپلانک می باشد . در این مقاله به روشهایی جهت بالا بردن کارایی سامانه اسپلانک با استفاده از منابع موجود خواهیم پرداخت:
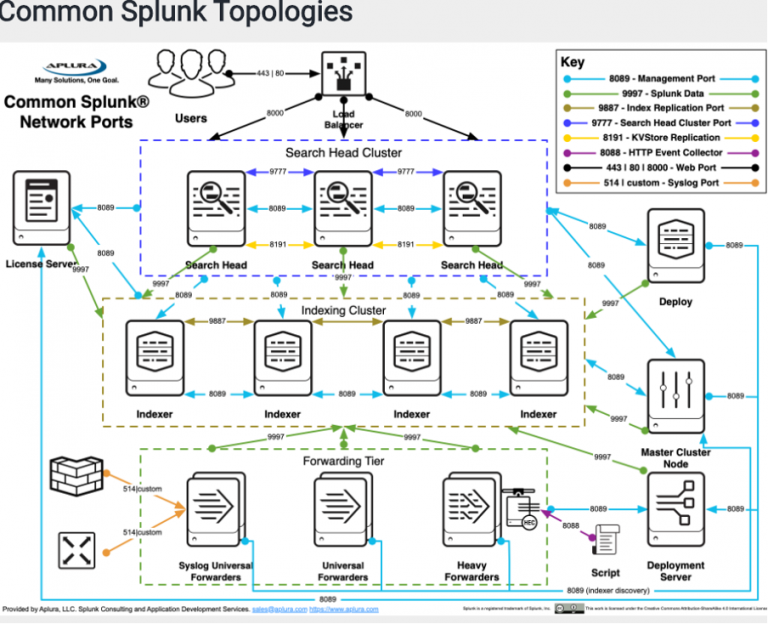
همانگونه که میدانیم معماری توزیع شده اسپلانک از سه لایه جستجو (search )، ذخیره سازی و Indexing، و جمع آوری لاگ (collection) تشکیل شده است . شایان ذکر است در ادامه به تغییر مقدار پیش فرض پارامترهایی در تنظیمات اسپلانک خواهیم پرداخت که هر سه لایه نامبرده را شامل می گردد.
۱. در لایه جستجو (search head)
-
تغییر مقدار max searches per cpu بر روی search head ها به مقدار 2
تاثیر: دو برابر شدن تعداد search های انجام شده به ازای هر cpu core
محل انجام تنظیمات : فایل limits.conf ماشین search head
مسیر:
SPLUNK_Home/etc/system/local/limits.conf
تنظیمات:
[search]
Max_searches_per_cpu = 2
۲. در لایه Indexing
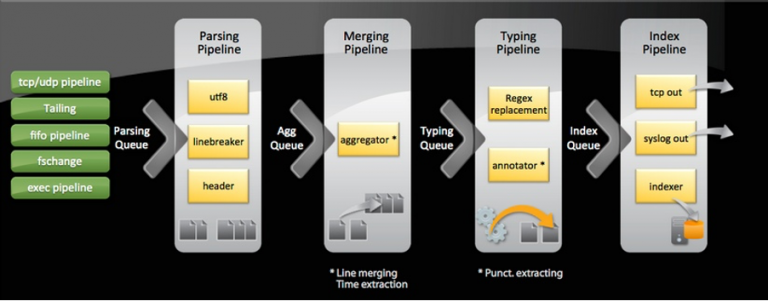
در حالت کلی اسپلانک پس از دریافت لاگ از لایه جمع آوری ، لاگهای دریافتی را از طریق pipeline ها پردازش می نماید. هر pipeline یک thread است که شامل چندین processor می باشد. بین pipeline ها queue وجود داشتع که توسط این pipeline ها و queue ها امکان پردازش موازی event ها در زمان index فراهم می گردد.
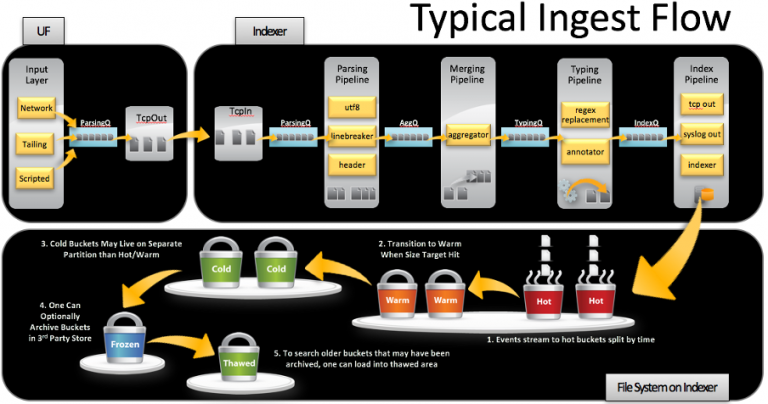
با تغییر تنظیمات پیش فرض مطابق با دستورات زیر، parallelization در این لایه صورت پذیرفته که تاثیر بسزایی در کارایی سامانه خواهد داشت:
-
تغییر مقدار Pipeline set ها به عدد 2
تاثیر: دو برابر شدن تعداد pipeline ها به ازای هر indexer
محل انجام تنظیمات : فایل server.conf ماشین های Indexer که میتوان از طریق Cluster Master تنظیمات اعمال گردد.
تنظیمات به صورت زیر می باشد:
مسیر:
SPLUNK_Home/etc/system/local/server.conf
تنظیمات:
[general]
parallelIngestionPipelines = 2
-
تغییر مقدار Batch mode search parallelization
تاثیر: دو برابر شدن تعداد pipeline های search در حالت batch search به ازای هر Indexer.
محل انجام تنظیمات : فایل limits.conf ماشین های Indexer که میتوان از طریق Cluster Masterتنظیمات اعمال گردد.
تنظیمات به صورت زیر می باشد:
مسیر:
SPLUNK_Home/etc/system/local/limitsl.conf
تنظیمات:
[search]
batch_search_max_pipeline = 2
-
تغییر مقدار auto summarize max concurrent
تاثیر: دو برابر شدن تعداد جستجوهای زمانبندی شده و accelerate شده به ازای هر search بر روی هر Indexer
محل انجام تنظیمات : فایل savedsearches.conf ماشین های Indexer که میتوان از طریق Cluster Masterتنظیمات اعمال گردد.
تنظیمات به صورت زیر می باشد:
مسیر:
SPLUNK_Home/etc/system/local/savedsearches.conf
تنظیمات:
auto_summarize.max_concurrent = 2
3. در لایه جمع آوری (Collection)
-
تعییر مقدار Pipeline set ها به عدد 2
تاثیر: دو برابر شدن تعداد pipeline ها به ازای هر indexer
محل انجام تنظیمات : فایل server.conf ماشین های Forwarder Heavy که میتوان از طریق deployment server تنظیمات اعمال گردد.
تنظیمات به صورت زیر می باشد:
مسیر:
SPLUNK_Home/etc/system/local/server.conf
تنظیمات:
[general]
parallelIngestionPipelines = 2
-
تغییر مقدار پیش فرض size queue
از آنجا که مقدار پیش فرض تنظیمات مربوط به queue برابر با 500KB میباشد ، در صورت دریافت حجم بالای لاگ در سطح forwarder منجر به پر شدن queue و drop شدن لاگ دریافتی خواهد گردید، در چنین شرایطی با توجه به میزان لاگ دریافتی توسط Forwarder تغییر این مقدار برای جلوگیری از بروز چنین مشکلی کار آمد می باشد.
تنظیمات به صورت زیر می باشد:
مسیر:
SPLUNK_Home/etc/system/local/server.conf
تنظیمات:
[queue]
maxSize = 2GB
-
غیرفعالسازی punct:
Punct یک فیلد پیش فرض اسپلانک است که الگوی آن به ازای هر نوع event مقداری unique میباشد.
این فیلد برای شناسایی شاخصه های تعیین کننده جهت ایجاد event type ها یا شناسایی anomaly ها بکار میرود.
همچنین این فیلد در زمان index بسیار بار پردازشی ایجاد مینماید که توصیه میشود در صورت عدم استفاده غیر فعال گردد.
نحوه غیر فعالسازی :
مسیر:
SPLUNK_Home/etc/system/local/props.conf
به ازای host، source و یا sourcetype مورد نطر در فایل props.conf عبارت ANNOTATE_PUNCT = false را وارد می نماییم:
مثال:
[syslog]
ANNOTATE_PUNCT = false